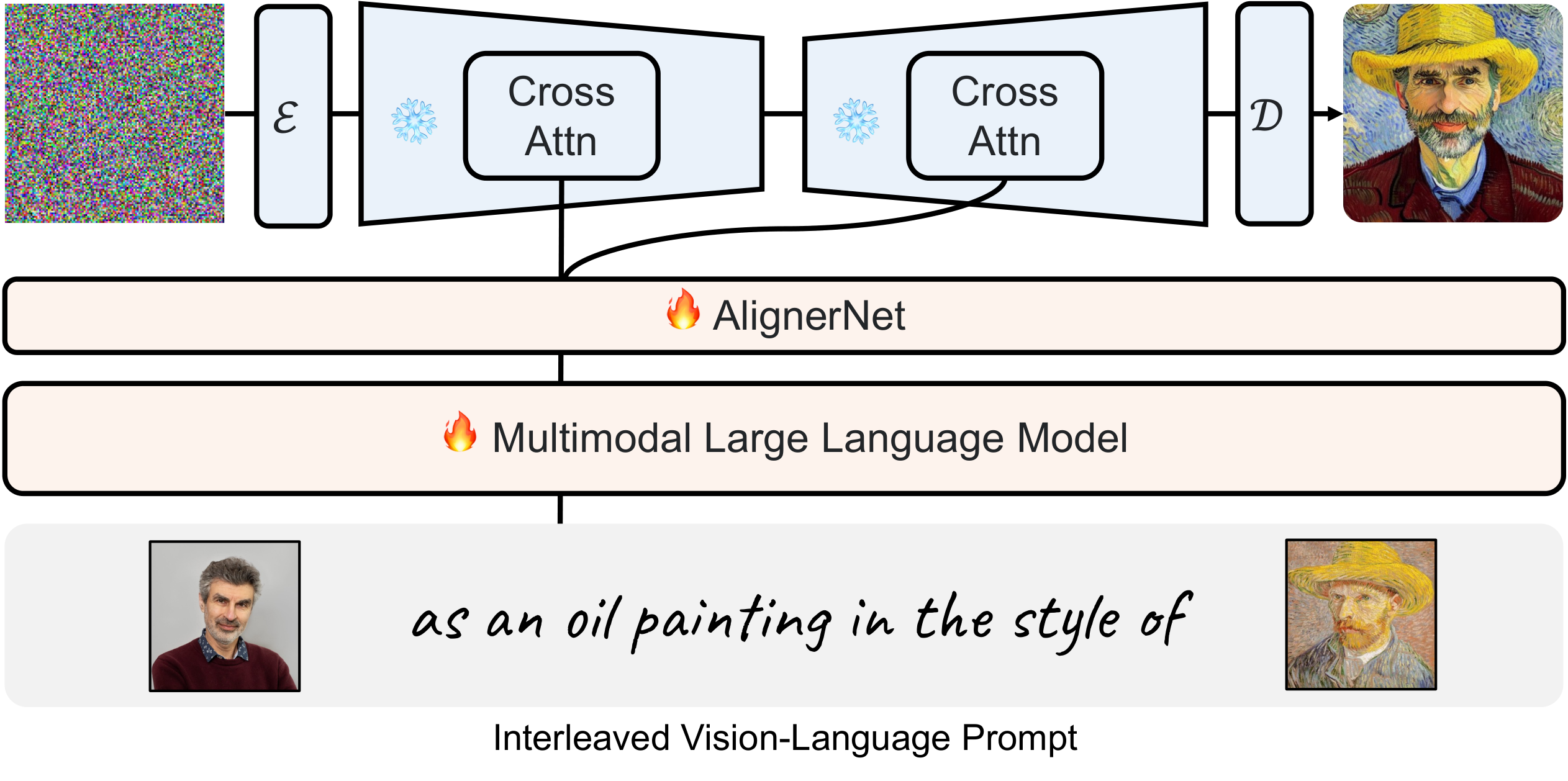
Kosmos-G is a model that can perceive general modalities, follow
instructions, and generate image conditions.
It comprises an MLLM for multimodal perception, coupled with an AlignerNet that bridges the MLLM to the
diffusion U-Net image decoder.
Kosmos-G can pass the fine concept-level
guidance from interleaved input to image decoder, and offer a seamless alternative to CLIP.
Specifically, the backbone of
Kosmos-G MLLM is a Transformer-based causal
language model, serving as a general-purpose interface to multimodal input. We train
Kosmos-G following an "align before instruct" manner, the entire training
pipeline can be divided into 3 stages:
- Multimodal Language Modeling: We pre-train the MLLM on multimodal corpora,
including monomodal data, cross-modal paired data, and interleaved multimodal data with language
modeling loss following Kosmos-1.
- Image Decoder Aligning: We use the U-Net of Stable Diffusion v1.5 as our image
decoder. We trained an AlignerNet on only textual data to align the output space of Kosmos-G to U-Net's input space through CLIP supervision. Here,
the language acts as the anchoring modality, ensuring image input is also compatible with the
image decoder.
- Instruction Tuning: We further fine-tune Kosmos-G
through a compositional generation task on curated data, with the differentiable gradient passed
from the frozen U-Net.
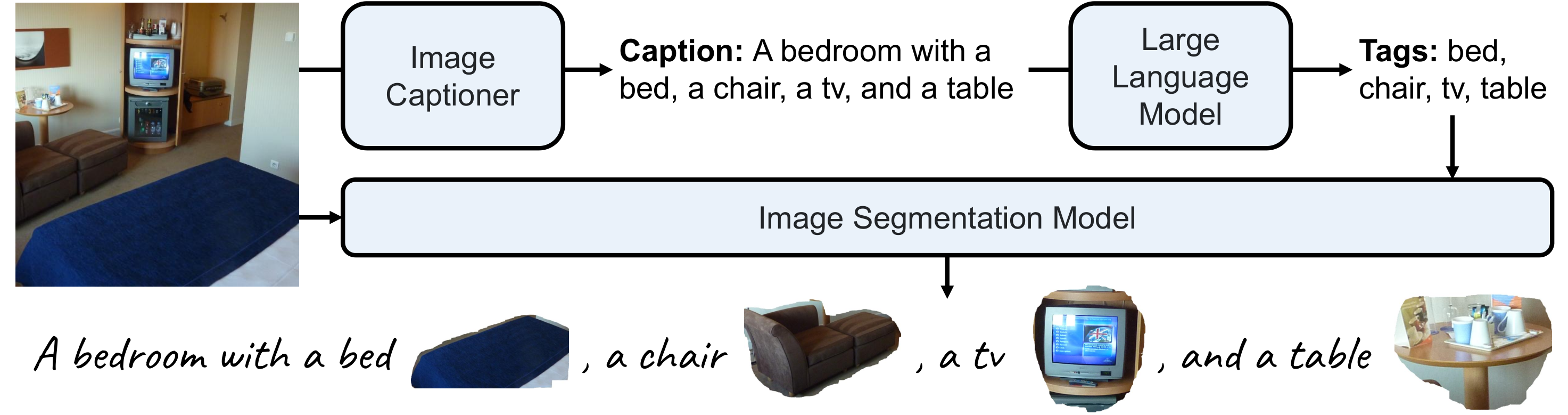
We construct a large-scale dataset based on OpenImage V7 for instruction tuning, which contains around 9
million images.